Practical 1: Python Refresher
1 Extracting the corpus from a wiki
1.1 Presentation of the wiki
For this practical, I decided to source the sentences in a wikimedia instance doing comparative stylistic between Breton and French: Style. Conveniently, the wiki contains a category of pages named “Korpus fr-br”, which is used to mark all the examples of translation analyzed in the wiki in a standard way using wikitext templates (here the template name is “Person” (reference to the book and its translation) and get passed several variables that we’re going to extract later):
{{person|fr=Après leur passage les femmes sortaient par les portes de derrière et couraient chez des amies dans l’espérance de précéder les messagères ; on se manquait souvent ou bien, à l’improviste, on se trouvait nez à nez l’une avec l’autre, et chacune déjà dûment avertie.|pajenn-fr=82|br=Goude ma oant bet ez ae ar maouezed all er-maez dre an dorioù dreñv ha d’ar red e ti o mignonezed, gant ar spi da erruout a-raok ar c’hannadezed; alies e veze c’hwitet war ar re all pe neuze e veze emgav fri-ouzh-fri, ha pep hini bet kelaouet evel m’eo dleet.|pajenn-br=61}}![[../assets/style_example.png]] Conveniently transcluded in the other articles like this:
==== Deskrivañ un obererezh kaset da benn en un doare dereat, evel m'eo gortozet ====
{{:Alies e veze c’hwitet war ar re all}}
{{:Evel m’eo dleet e priente ar gerent da veilhat un toulladig eurvezhioù}}Which shows like this in a normal article:
![]()
1.2 Extracting the corpus
The French-Breton corpus is accessible here.
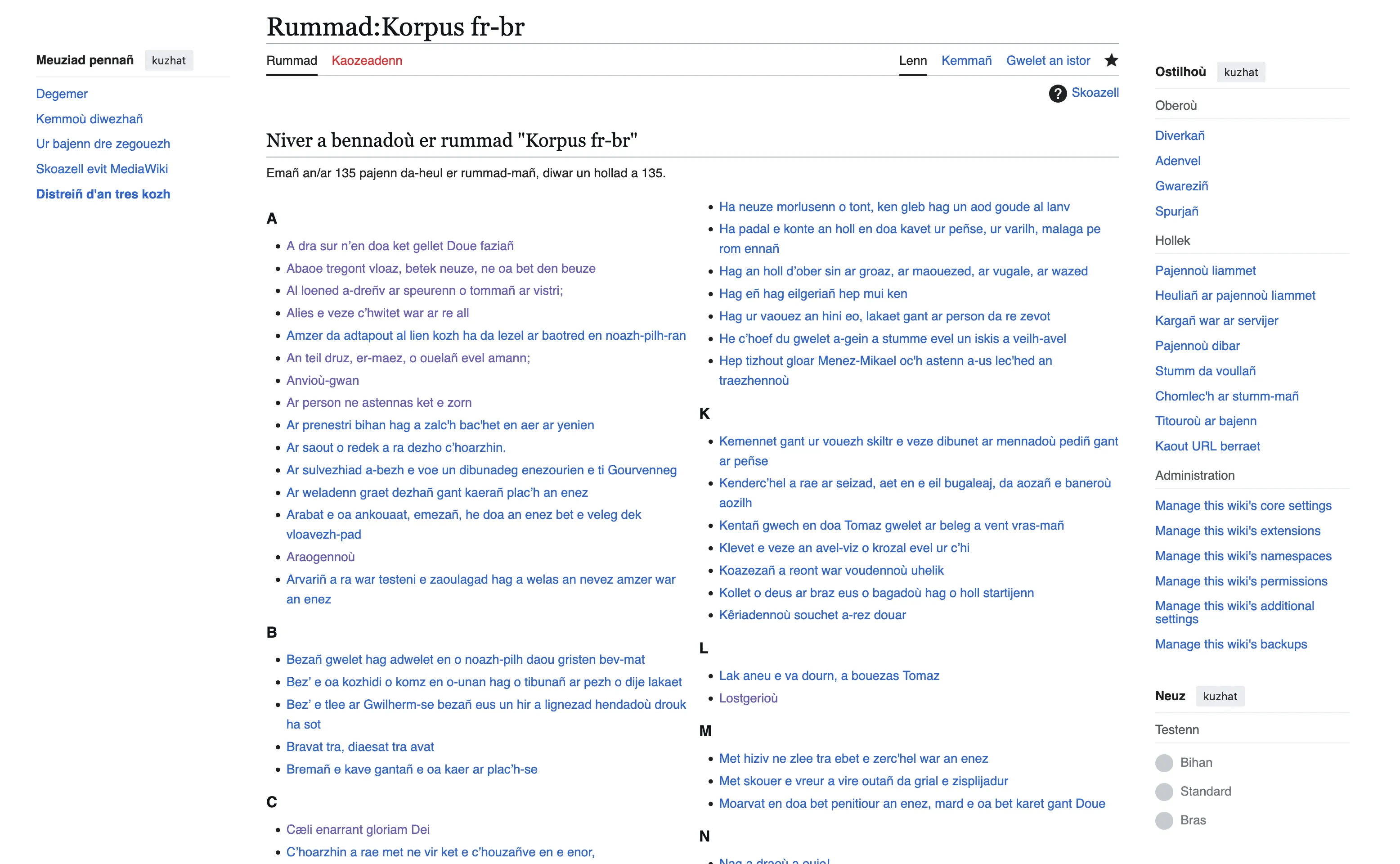 From this category page we can access all the examples used in the wiki. Then, we load them in a json file to analyse these examples later. You can find the code used for the extraction as well as the extracted corpus here on my GitHub.
From this category page we can access all the examples used in the wiki. Then, we load them in a json file to analyse these examples later. You can find the code used for the extraction as well as the extracted corpus here on my GitHub.
2 Analyzing a sentence
Here is a graph of the dependencies in one of the French sentences of the corpus. I could not analyze a Breton sentence as precisely because Here is the same sentence analized as a list of token, parts of speech (POS), and stops:
Les DET Trueanimaux NOUN False, PUNCT Falsederrière ADP Truela DET Truecloison NOUN False, PUNCT Falsequi PRON Trueréchauffent VERB Falseles DET Truemaîtres NOUN False; PUNCT False3 Counting the tokens
50 most common alphabetic tokens:In the French examples:[('prêtre', 17), ('Dieu', 16), ('île', 15), ('Thomas', 12), ('homme', 10), ('mer', 10), ('devoir', 9), ('falloir', 8), ('contre', 8), ('femme', 7), ('îlien', 7), ('ciel', 7), ('rien', 7), ('bel', 6), ('faire', 6), ('ile', 6), ('paroisse', 6), ('nuit', 6), ('église', 6), ('tandis', 5), ('bien', 5), ('temps', 5), ('main', 5), ('avoir', 5), ('chrétien', 5), ('haute', 5), ('prière', 5), ('entendre', 5), ('année', 4), ('oeil', 4), ('recteur', 4), ('pêcheur', 4), ('petit', 4), ('fenêtre', 4), ('vent', 4), ('long', 4), ('posséder', 4), ('chose', 4), ('être', 4), ('bon', 4), ('prendre', 4), ('épave', 4), ('voix', 4), ('grève', 4), ('rendre', 4), ('lieu', 4), ('récif', 4), ('pauvre', 4), ('envoyer', 4), ('tête', 4)]
In the Breton examples:[('gant', 43), ('enez', 20), ('ouzh', 20), ('evit', 15), ('evel', 14), ("d'ar", 13), ('beleg', 13), ('doue', 12), ('tomaz', 12), ('veze', 11), ('dezhañ', 11), ('vefe', 11), ('neuze', 9), ('bezañ', 9), ('oant', 8), ('holl', 8), ('reas', 8), ('dleet', 7), ("d'an", 7), ('mont', 7), ('enezourien', 6), ('gwelet', 6), ('daoust', 6), ('oabl', 6), ('goude', 5), ('maouezed', 5), ('lakaet', 5), ('gantañ', 5), ('iliz', 5), ('unan', 5), ('peñse', 5), ('vont', 5), ('sevel', 5), ('anezhañ', 5), ('daou', 4), ('a-raok', 4), ('person', 4), ('nemet', 4), ('lakaat', 4), ('dezho', 4), ('douar', 4), ('anezho', 4), ('heul', 4), ("c'helle", 4), ('diouzh', 4), ('penn', 4), ('aotrou', 4), ('klevet', 4), ('gellet', 3), ('betek', 3)]Surprizingly, the word for “God” appears 16 times in French and only 12 times in Breton, but the word for “island” is much more present in Breton than in French. This might be because of the mutations and other sorts of inflections found in Breton, might have the counter ending up counting different forms of the same words separately. Which does not show up when selecting the most frequent words.
I don’t want to elaborate more on the nature of the difference between types and token, the Zipft law and the Heap law, you can always read what I said in a previous assignment here.
4 Words Cloud
I used the 50 most common Breton words above to generate the following word cloud.
