Ymarferol 4: Speech Recognition
1 Start Using transcription Models
1.1 Youtube video transcription
I like to learn about the economy with the “How Money Works” YouTube channel. But I often find myself unable to recall the three main arguments of a video after watching it. So I figured out I would transcribe one video and feed the trancription in an LLM to have it summarizing the content to me. First I chose Meta’s wav2vec2 model:
model_name = "facebook/wav2vec2-base-960h"In terms of parameters, I tried different chunk lengths, from 5 to 60 and figured out that the duration of the transcription was shorter with chunks of around 50ms. For the stride length, shorter values ran actually faster, but most likely using more GPU, I could not find a detail enough graphs on Google Colab. I just saw that the model was burning a low percentage of GPU but without striking differences between the different calls.
Regarding the accuracy we can find some mistakes here an there, like ’ NOBODY COULD GET ALONE’ for “nobody could get a loan”, changing chunks from 50 to 10 and the strides from 10 to 1 did not improve this mistake, but help with some others, like the word “INSTITUTIONR” rightfully being corrected to “INSTITUTIONAL”. This small gain in accuracy comes at the expence of a total transcription time of slitely over 3 seconds, 3.082805871963501 when around 2.917 with a chunk length of 50ms. But using a CPU to make the transcription, the process took 295 seconds, that is 4’55”, I could not notice a surge in the RAM usage graph, around 3 GB.
Despite some mistakes, and the absence of punctuation marks, the whole text is easily readable. I could use Mistral to sumarize me the content of the video, here is the link to my conversation with Mistral.
1.2 Feature Extraction
I removed the feature_extractor.hop_lengths reasignment before reading this exercise instruction to get the model work. The hop length is in my understanding the stride length mentioned above, and it’s value sould stay relatively low, default is 160.
As I happened to have a harp under my hand when doing this practical, made my own recording of an arpeggio with it. Here is the spectrogram of the recording on audacity.
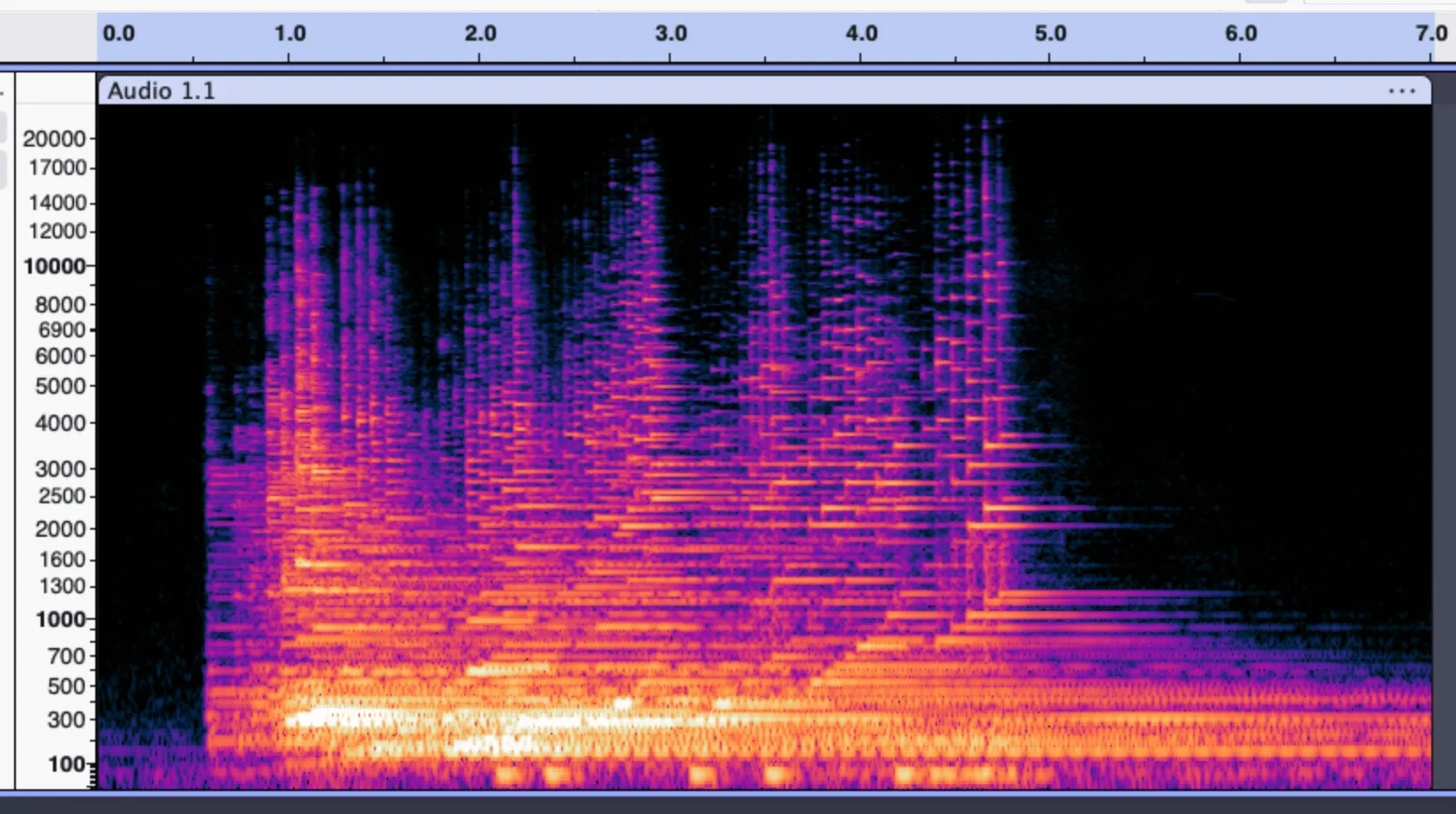 And here is the mel spectrogram generated with python.
![[../assets/mel-arpeggio.png]]
I don’t see any striking difference between the two. The only difference seems to be the absence of frequencies higher than 4096Hz, which is commonly called a low-pass filter in acoustic this may be related to the lower sampling rate of 16 000 which erases higher pitches.
And here is the mel spectrogram generated with python.
![[../assets/mel-arpeggio.png]]
I don’t see any striking difference between the two. The only difference seems to be the absence of frequencies higher than 4096Hz, which is commonly called a low-pass filter in acoustic this may be related to the lower sampling rate of 16 000 which erases higher pitches.
2 Fine-tuning a model
Complete the training and evaluation steps and report what is your WER. If you used the ‘Explain error’ button, then report what error did it explain to you and what advice did you follow. If your training and evaluation doesn’t work, then answer the questions below to ensure marks… Report on the datasets you used and which splits you used for what purpose. Report why did you choose the datasets and spits? What kind of transcriptions were you aiming of obtaining from your model? What machine learning training technique, that has been discussed so far in lectures (in the entire module), that could be employed to aid optimizing your training hyperparameters more robustly, especially when you have limited data.
As I tried to fine-tune whisper the first time, I ran out of memory, so I changed the run time twice to end up with an A100 GPU (28GB out of 40GB available were necessary), the second time I also diminished the size of the training dataset, limiting it to 50 examples… I initially thought that when selecting ranges, I selected batches, and that in these 50 batches represented hundreds of examples… I realized that it wasn’t the case much later and I will not fine tune the model again as I am running out of compute units.
Here is a code block that I added to make my testing dataset. Note that the validation dataset initially used common voice’s test split and that the training dataset contained CV’s validation set, I corrected both those errors in the initial code.
dsTest = datasets.load_dataset("mozilla-foundation/common_voice_17_0", "cy", split="test")
dsTest = dsTest.select(range(15))
dsTest = dsTest.map(prepare_dataset, num_proc=1)model.half() # I also had to add this line for reasons.If I had to do the fine-tuning again, I would start by evaluating the base model with the same testing dataset before and after the process to evaluate the gains. But as mentioned earlier, I am running out of compute units. I initially got a WER of 229.99999999999997%, but that’s because of my misunderstanding of the datasets length selection. My initial datasat only contained 5 examples. When I tried again with 15 (still not enough) I got 86,20689655172413%… Not great, but at least it is below a 100…